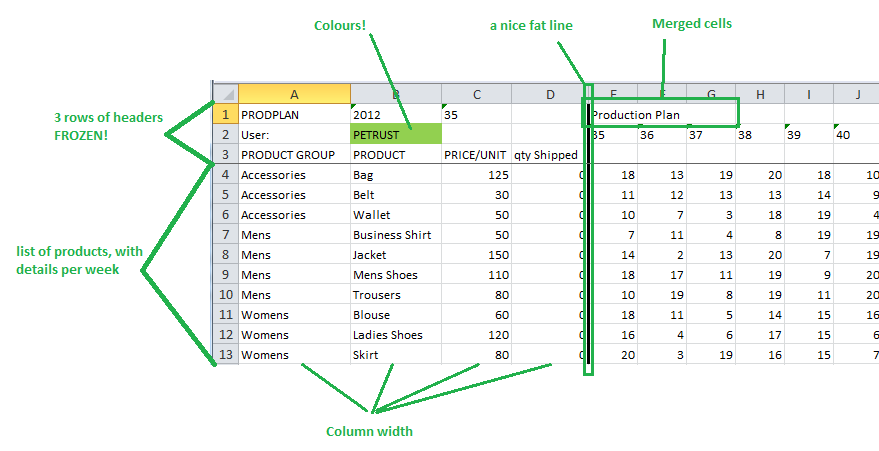
Refer to the fantastic diagromographic to see what I created! Bliss.
Why, Tom?
Standard CSV export is not able to do this. No formatting, no styling, freezing headers. A report was also no option, since that is not the point of this file.During a migration project there was this excel being used somewhere. It was on the server machine of the database, because it had to have access to an oracle client so it could connect through use of macros. These macros would load in data in 3 extra sheets in the workbook, so that on the first sheet a vertical lookup could gather data from those sheets. Full tables there!
The generated excel would then be saved without macros, and sent to distributors who could then check the information and alter columns where necessary. An example would be to alter the production values with their corrected values. They would then save the excel and send it back.
This excel would then be opened and saved as a csv. This csv was then to be placed in a specific drive/folder of the same server machine it was created on, so that a scheduled task could pick it up to serve it to a processing procedure, which would read line per line.
The question then was: can we move a part of all of this to apex?
What happens now is: to generate the excel the user navigates to an apex page, selects the required parameters, and the excel is generated and served to download. Any required alterations are made, and the excel is sent to the distributor(s). There any required alterations are made, and the excel is sent back. It then can simply be uploaded and processed.
No more macros, vlookups, save to csv, no more client or scheduled tasks or access to machines with an oracle client. There are 2 apex screens with some parameters and that’s it.
Also, there is almost no change in the look of the excel file the distributors get sent. This was quite crucial too: with lots and lots of distributors, changing the look and potentially the working method was not an option (well, it would have cost a lot of time and effort). Only the end point interaction has changed, and those people were easily trained.
Sample Application
http://apex.oracle.com/pls/apex/f?p=10063How it works
I’ll briefly touch on how things are set up. You can check how it works on my sample app on apex.oracle.com, and you can download the sample application. It includes the database objects such as tables, sequences and packages and some data seeding in the Supporting Objects. The deinstallation script is also in place and will drop all objects the supporting objects create.Now first of all, I’ve used some packages from the Alexandria PLSQL library: a great project bundling a lot of interesting packages and information. In my supporting objects I only included the bare minimum of objects required to make the application work (sql_util, zip_util, xlsx_builder).
Props to Anton Scheffer, for his blogs and his xlsx_builder package: http://technology.amis.nl/2011/02/19/create-an-excel-file-with-plsql/
And to Odie, check this mind-boggling blogpost: http://odieweblog.wordpress.com/2012/01/28/xml-db-events-reading-an-open-office-xml-document-xlsx/
Generating
In short, all it does is use the xlsx_builder_pkg api. All the things pointed out in the picturesque diagramographic can be done through it. Those less familiar with plsql code can take a look at how I built the excel and build on it. If you’re concerned about performance, I’m not really. A download really goes very fast, about 1-2 seconds for ~200 records and 26 weeks: 200 rows *31 cells. It really does depend on having a performant select-statement, since the xlsx-builder is in-memory.As a “bonus”, the generating code also holds some week-creation voodoo. The first week is retrieved, and further date arithmetic is done based on this initial date.
Serving as download
This may not be all that new to you if you had to offer files up for download before. Basically I call my package which generates the excel file and returns it as a blob. Then I set some http headers. The file is then served as a download through wpg_docload, and finally the page processing is called to a halt.DECLARE
l_excel BLOB;
BEGIN
l_excel := demo_product_excel_pkg.create_excel
(
p_week => :P1_WEEKNR
,p_year => :P1_YEAR
,p_nr_weeks => :P1_WEEKS_AMOUNT
,p_user => :APP_USER
);
-- Prepare Headers
owa_util.mime_header('application/vnd.openxmlformats-officedocument.spreadsheetml.sheet',FALSE);
htp.p('Content-Length: '||dbms_lob.getlength(l_excel));
htp.p( 'Content-Disposition: filename="PRODUCT_PRODPLAN_' || '2012' ||'_'|| '35' || '.xlsx' || '"' );
owa_util.http_header_close;
wpg_docload.download_file(l_excel);
apex_application.g_unrecoverable_error := true;
END;
Uploading
The selected file is uploaded to the wwv_flow_files table, so the first thing that has to happen is to get this blob. It is then passed on to the package for processing. Finally, the record is removed from wwv_flow_files.Processing
The processing is something I changed a lot to. The Alexandria plsql library has, as you may have noticed, an ooxml_util package with which you can read an xlsx file. However, it wasn’t 100% what I was looking for and not as fast as I’d wanted.For example, the get_xlsx_cell_value function takes the excel file as a blob. This means that multiple calls will each take the blob, unzip it and get the value.
Function get_xlsx_cell_values can retrieve an array of cells, but requires you to define that array beforehand.
Function get_xlsx_cell_values_as_sheet has the same issue as the regular cell_values.
Function get_xlsx_cell_array_by_range is a lot more interesting: it’ll retrieve all cells starting from a cell to a cell, and give them back in an array.
Still I was not satisfied, so I went alternative. I started by copying over the functions get_xml, get_worksheet_file_name and get_xlsx_column_number. This way I’d be able to open the excel blob and retrieve the xml just once, and do my reads on them. I also kept things simple. My excel sheet IS simple. There are numbers and text there, and that is all that matters to me.
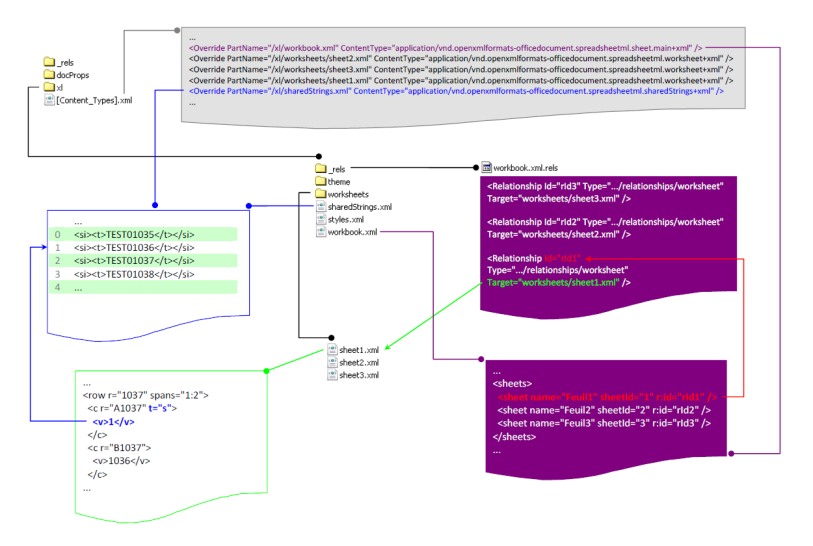
See this diagram about the ooxml structure (all props to Odie – see the large image on his blog)
I decided to directly read the xml files I require, pump them in temp tables, and join those together to get my result. This means: read the rows and values, and fetch shared strings where required.
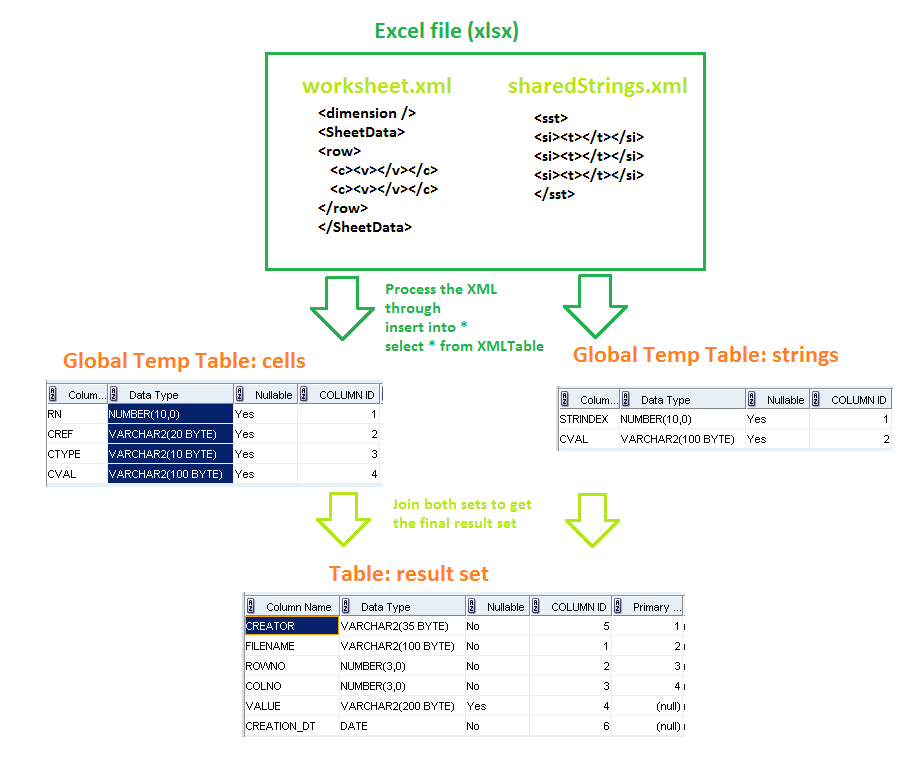
Another wonderful paintjob brought to you, by me.
-- Process the sheet data
-- get each row element and extract the column elements as an xmltype
-- then process this column xml and extract the values
INSERT INTO DEMO_LOAD_EXCEL_CELLS_GTT (rn, cref, cval, ctype)
SELECT wsx.rn, wsc.cn, wsc.val, wsc.type
FROM xmltable(xmlnamespaces(default 'http://schemas.openxmlformats.org/spreadsheetml/2006/main'),
'/worksheet/sheetData/row'
passing l_xml
columns rn number path '@r' , cells xmltype path 'c') wsx,
xmltable(xmlnamespaces(default 'http://schemas.openxmlformats.org/spreadsheetml/2006/main'),
'/c'
passing wsx.cells
columns cn varchar2(30) path '@r'
, val number path 'v'
, type varchar2(10) path '@t') wsc;
-- Process the shared strings xml
-- get the shared strings extracted from the sst element
-- Their order defines their index which is to be zero-based
INSERT INTO DEMO_LOAD_EXCEL_SHSTR_GTT (strindex, cval)
SELECT (rownum-1) ssi, wsss.val
FROM xmltable(xmlnamespaces(default 'http://schemas.openxmlformats.org/spreadsheetml/2006/main'),
'/sst'
passing l_shared_strings
columns val xmltype path 'si') wss,
xmltable(xmlnamespaces(default 'http://schemas.openxmlformats.org/spreadsheetml/2006/main'),
'/si'
passing
wss.val
columns val varchar2(100) path 't') wsss;
Then these are put in the final table: INSERT INTO DEMO_LOAD_PRODPLAN (run_id, creator, filename, rowno, colno, value)
SELECT l_run_id, l_user, l_file_name, c.rn, get_xlsx_column_number(regexp_replace(c.cref, '[0-9]', '')), nvl(s.cval, c.cval)
FROM DEMO_LOAD_EXCEL_CELLS_GTT c
LEFT OUTER
JOIN DEMO_LOAD_EXCEL_SHSTR_GTT s
ON c.ctype = 's' AND c.cval = s.strindex;
Which then results in:
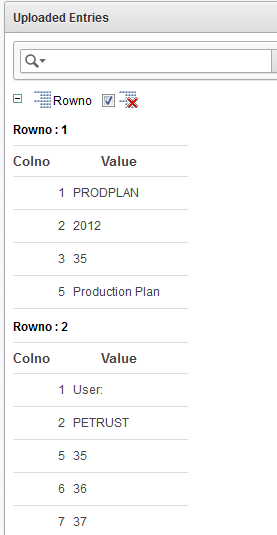
Since the “width” of a table (columns) is not a dynamic things, it was never my intention of trying to achieve that. How many columns would you need? How will you iterate over it? Are you going to write checks for each column or even cell?
It made a lot more sense to store each value with a row and column number. And in my case I was able to change the original code which read line per line without a lot of impact. I can simply iterate over each row (line), and each value has a position (column): same as if you’d read a comma-separated line.
Ok, so that was not briefly. Sue me.
Enjoy! =)
Hi Tom,
ReplyDeleteJust a few comments about querying the sharedStrings document. It's recommended to use the FOR ORDINALITY clause to get the node position in document order (instead of ROWNUM).
You may also use a single XMLTable, there's no need to extract 'sst' element first and 'si' after :
XMLTable(
XMLNamespaces(default 'http://schemas.openxmlformats.org/spreadsheetml/2006/main')
, '/sst/si'
passing l_shared_strings
columns idx for ordinality
, val varchar2(4000) path 't'
)
If you're interested in parsing performance, you may also try to first store the document in a binary XMLType table and query from there afterwards.
Hi Odie,
DeleteThank you for the feedback. I'll certainly implement those changes.
And of course i'm interested in parsing performance since this is still the slowest step currently. Would i actually gain by saving the XMLs to a table? Right now the file is uploaded as a blob from which i get the 2 xmls. These xmls are XMLTYPE variables. I take it these are in-memory, so wouldn't this be the fastest i could get already?
Yes, storing your XML documents in a Binary XMLType column will increase the performance dramatically.
DeleteBinary XML is a post-parsed format that is optimized for storage and XQuery operations (XPath streaming evaluation).
On the contrary, using in-memory parsing all along is the slowest approach because Oracle will use functional evaluation of XQuery (via an intermediate DOM object).
BTW, Binary XML is an 11g feature only. You can see how to use it throughout the rest of the article on my blog, including how to create XML indexes.
has errors ORA-06508: PL/SQL: could not find program unit being called: "ESQUEMA_1.XLSX_BUILDER_PKG"
ReplyDeletewhere is the package XLSX_BUILDER_PKG?
ReplyDeleteThere are installation scripts included in the supporting objects of the application. That package is one of them.
DeleteHi Tom,
ReplyDeletethanks for your blog post and useful code. I successfully applied excel downloading functionality. When trying to use excel upload I face the problem with Data Types - Number and Date. The content of both is transformed during the upload even if the cell format is correctly set.
Did you face it, too? Can you give me any advice how to fix it?
Regards,
Frantisek